
A Prompt Crafting Framework for Generative AI

What separates a good prompt from a trivial one? The major AI literacy frameworks all agree that students need to learn how to prompt generative AI well. None of them say much about what to teach. The prompt engineering literature, meanwhile, is rich with techniques and benchmark results, but it is mostly addressed to engineers and mostly measured by task accuracy. An educator who accepts that prompting is a core skill of the AI era still faces a granular problem: what exactly should students learn to see in a prompt, to design in a prompt, and to evaluate after a prompt has been tested?
This post lays out a framework for teaching prompt crafting in higher education. It is the blog version of a manuscript, and it grows out of my work teaching Generative AI and Prompting at UCalgary.

From Prompt Engineering to Prompt Crafting
A note on terminology before we go further. The dominant term in the technical literature is prompt engineering, which emphasizes the optimization of prompts for measurable system performance. I prefer prompt crafting because it captures something more important. This is judgment-laden, situationally appropriate work that is part art and part science, and it belongs in every discipline. It is a skill for everyone to learn. The term also aligns with recent work treating prompt design as a reflective professional practice that involves real judgment.
Here is the definition I work with. Prompt crafting is the deliberate design of prompts beyond the trivial, in order to achieve valuable outcomes that would otherwise be difficult to reach reliably with the same AI system. By trivial I mean what an average user would write intuitively for the same task. We don't need a framework to teach people to type "summarize this article." We need a framework for the part where deliberate design starts paying dividends.
The Three Layers
The framework has three layers, and they answer three different questions:
- Design Dimensions (Layer 1): What kinds of moves can a prompt make?
- Qualities of Practice (Layer 2): How well are those moves handled?
- Value Outcomes (Layer 3): What kinds of value can a prompt produce?
The layers are conceptually distinct on purpose. Layer 1 is about the structural features of the prompt itself. Layer 2 is about evaluative standards for those structural features. Layer 3 is about downstream consequences. Skilled prompt crafting is the integration of all three: choosing the right moves, making them well, in service of the right outcomes.
Let me walk through each layer.
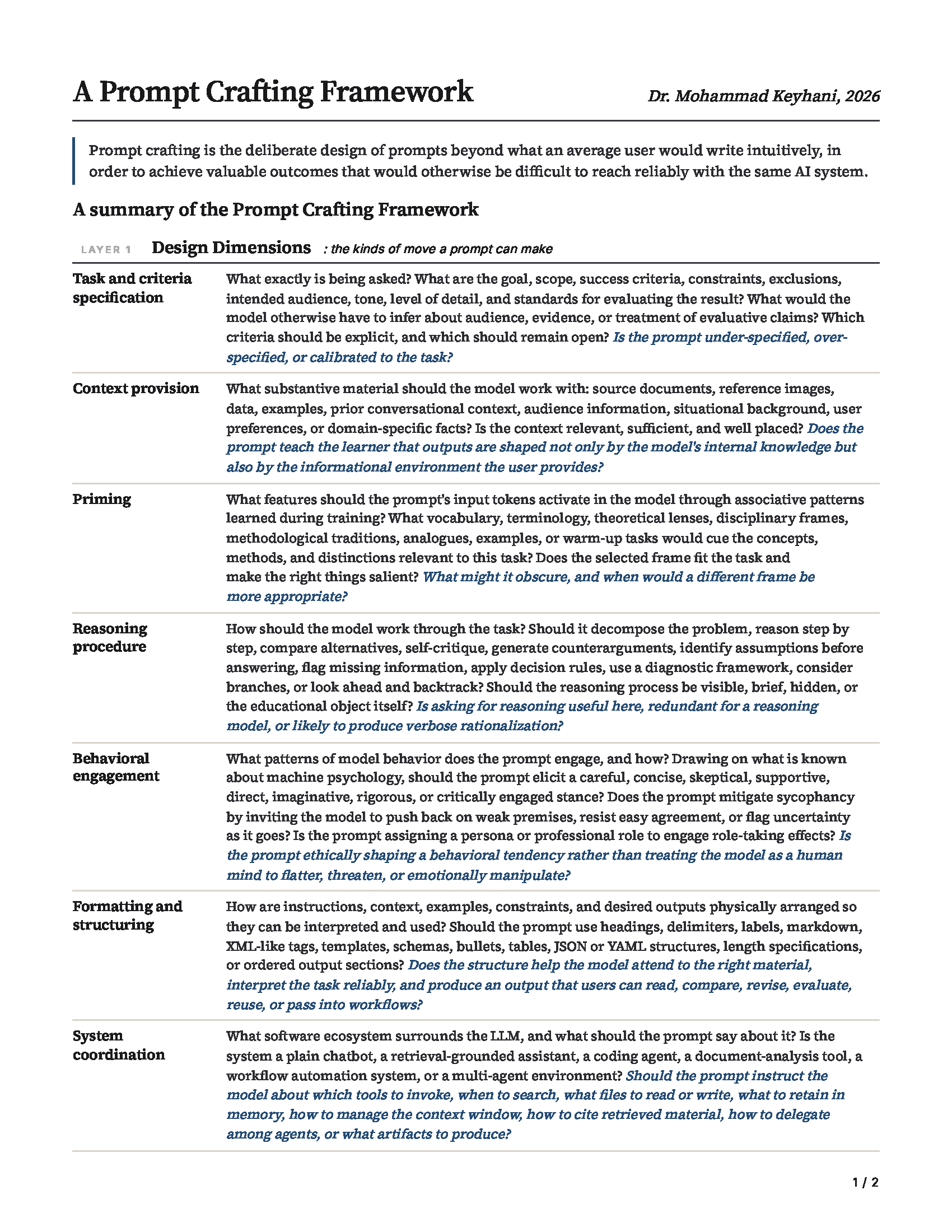
Layer 1: Seven Design Dimensions
1. Task and Criteria Specification. What is being asked, and by what standards will the result be evaluated? This includes the goal, scope, success criteria, constraints, exclusions, intended audience, and tone. A prompt that says "summarize this article" leaves a lot for the model to infer. A prompt that says "summarize this article in a way useful for a non-specialist audience, foregrounding the main claim and the strongest evidence, separating descriptive from evaluative claims" is exercising this dimension deeply. The physical shape of the output (word count, sections, schema) belongs to formatting. Audience and tone are evaluative criteria. Word count is physical form.
2. Context Provision. What substantive material should the model work with? This includes source documents, data, examples, prior conversational context, audience information, situational background, user preferences, and domain-specific facts. Few-shot prompting, where you supply examples of the desired input-output relationship, is a canonical case. The effective use of this dimension depends on relevance, sufficiency, and placement. Irrelevant material can distract the model. Long context dumps can bury relevant information in the middle of the context window where models tend to use it poorly. The pedagogical point is that model outputs are shaped by what users provide as much as by what the model knows. Andrej Karpathy famously described the closely related discipline of context engineering as the delicate art of filling the context window with just the right information.
3. Formatting and Structuring. How is the prompt physically arranged, and what shape should the response take? This includes headings, delimiters, labels, markdown, XML-like tags, schemas, bullets, tables, JSON or YAML, length specifications, and ordered output sections. The reason this matters is empirical: Sclar et al. showed that meaning-preserving formatting changes alone can shift model performance by significant margins. Structure is not cosmetic.
4. Priming. Priming exploits the associative structure of the model: the fact that input tokens activate features statistically associated with them during training. When you choose terminology, theoretical lenses, disciplinary vocabulary, methodological traditions, or analogues, you are shifting the probability distribution over what the model produces. The mechanism is the same one cognitive psychologists have long studied in humans: prior exposure makes related concepts more accessible. In LLMs the effect is even more direct, because at their core these models just are statistical predictors of the next token given the input.
A good example of priming is the GPT-5 science acceleration experiment by Bubeck et al. The model initially failed to identify the Lie point symmetries of a curved-space black hole equation. When the researchers first gave it a simpler flat-space version of the problem, the model solved that warm-up and then succeeded on the harder problem in the same conversation. The simpler case had primed the relevant pattern.
5. Reasoning Procedure. How should the model work through the task? This is the dimension behind chain-of-thought prompting, zero-shot "think step by step", and self-consistency. It includes decomposition strategies, stepwise reasoning, comparison procedures, self-critique, counterargument generation, decision rules, diagnostic frameworks, and procedural epistemic steps like "list your assumptions before answering." The route the model is asked to take matters. With reasoning models that already think before they answer, asking for explicit reasoning may be redundant or may produce verbose rationalization, so this dimension also includes the judgment of when not to specify a reasoning procedure.
6. Behavioral Engagement. This is the dimension that exploits everything we know about machine psychology. Where priming exploits associative feature activation at the level of mechanism, behavioral engagement exploits regularities at the level of observed model conduct. We know that models can be sycophantic, aligning with stated user beliefs in ways that degrade truthfulness. We know they exhibit various decision biases and stance shifts in response to certain cues. Behavioral engagement is the dimension through which the prompt accounts for these patterns: asking the model to be skeptical, to push back when it disagrees, to flag uncertainty as it goes, or to adopt a persona that engages role-taking effects.
Priming and behavioral engagement operate at two different levels. Priming changes what the input activates in the neural network. Behavioral engagement engages known patterns of model behavior. Some moves operate on both levels. "Act as a contract lawyer" primes legal vocabulary and engages role-taking behavior, for example. The underlying principles, though, are distinct.
7. System Coordination. The AI systems we prompt have become remarkably diverse. A user today may be prompting a plain chatbot, a retrieval-grounded assistant, a coding agent, a document-analysis tool, an agent harness, or a multi-agent research environment. System coordination is the dimension through which the prompt instructs the model about everything in the software ecosystem around the LLM that is not the LLM itself. Which tools to invoke. When to search. What files to read or write. What to retain in memory. How to manage the context window. How to delegate among agents.
This dimension is bounded by a clear principle. It concerns the surrounding software. Instructions about how the model should reason about missing evidence belong to reasoning procedure. Instructions about whether the model should ask the user for clarification belong to behavioral engagement. System coordination is reserved for moves that address the surrounding software.
The pedagogical value of this dimension is that it forces learners to stop treating all AI systems as interchangeable chat windows. A prompt that works well in a vanilla chatbot may fail completely in an agentic environment, and vice versa. As I argued in my recent post on judgment-powered software, the most consequential AI products of the next few years are going to be agentic systems and not simple chatbots.
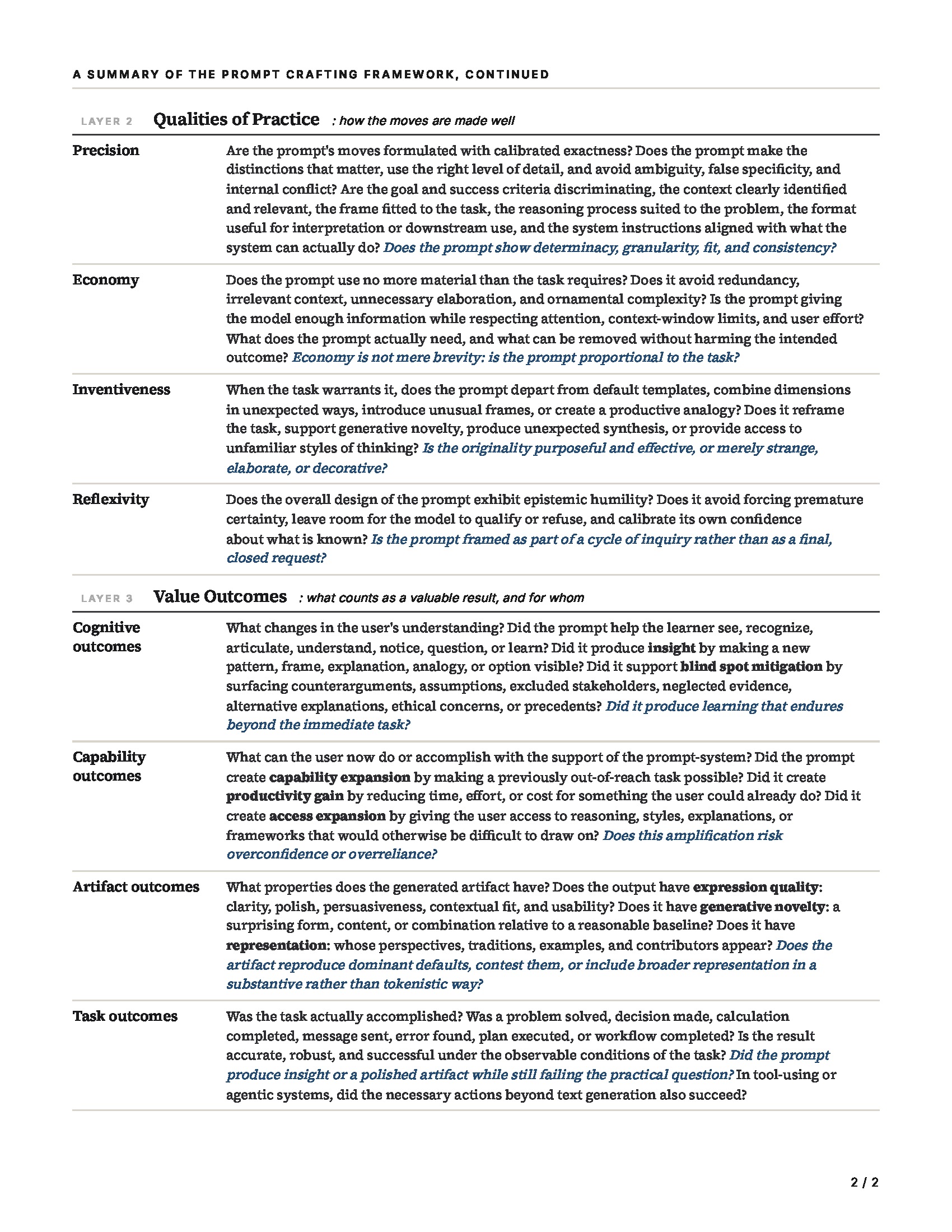
Layer 2: Four Qualities of Practice
If Layer 1 talks about the moves a prompt can make, Layer 2 asks how well those moves are made. The qualities cut across the dimensions. A prompt can be precise in its task specification, economical in its context provision, inventive in its priming, and reflexive in its behavioral engagement.
Precision. The calibrated exactness with which a prompt's moves are formulated. A precise prompt makes the distinctions that matter for the task, uses the right level of detail, and avoids ambiguity, false specificity, and internal conflict. A prompt that says "give an exhaustive analysis in 100 words" is imprecise. A prompt that says "rely only on the attached document but also include current external developments" is imprecise. Precision is the quality by which a prompt's parts cohere.
Economy. The use of no more material than the task requires. Long prompts are not automatically better prompts. Long contexts dilute attention, bury relevant information, increase cost, and make failures harder to diagnose. Economy is not the same as brevity, though. A short prompt can be under-specified. A long prompt can be economical if the task genuinely requires extensive context. The right question is whether the prompt is proportional to the task.
Inventiveness. The originality with which prompt moves are chosen and combined. Most prompts don't need this. A compliance summary or a spreadsheet formula rewards precision and economy. But when the task benefits from reframing, unexpected synthesis, or access to unfamiliar styles of thinking, inventive prompting becomes important. Doshi and Hauser found that generative AI tends to improve individually rated creative writing while reducing the collective diversity of generated stories. There is a convergence toward the most likely response. Inventive prompting is how you push against that convergence.
Reflexivity. Reflexivity is the epistemic posture exhibited by a prompt as a whole. A reflexive prompt does not force premature certainty on the model or itself. It leaves room for qualification, refusal, and correction. It calibrates its own confidence about what is known and unknown. And it is framed as part of a cycle of inquiry. Reflexivity has direct antecedents in Donald Schön's classic work on reflective practice and in recent work treating prompt engineering as a reflective professional practice.
Importantly, reflexivity is a quality and operates differently from a category of moves. Specific moves that invoke reflexive behavior in the model (asking it to push back, identify assumptions, flag uncertainty) are Layer 1 moves under behavioral engagement or reasoning procedure. What makes a prompt reflexive at the level of quality is whether its overall design exhibits humility about what the user knows, what the model knows, and what the interaction is for. A prompt can include all the right reflexive-looking moves and still lack reflexivity in its overall design. For example, a prompt might ask the model to identify assumptions while elsewhere strongly signaling the conclusion the user wants.
Layer 3: Four Loci of Value Outcomes
Task accuracy is an important outcome, and other kinds of value matter too in education. A student may learn from an interaction even when the immediate answer is imperfect. A prompt may produce a polished artifact without deepening anyone's understanding. The outcomes layer helps learners and educators distinguish these kinds of value. I organize outcomes by locus, by which I mean the place where the value resides.
Cognitive outcomes reside in the user's understanding. They are changes in what the user can see, recognize, articulate, or understand. Three subtypes are especially useful. Insight is in-the-moment recognition, when a new pattern or frame becomes visible. Blind spot mitigation is the surfacing of considerations the user did not know were missing. Learning is durable cognitive gain that persists beyond the immediate task. Cognitive outcomes locate value in the learner, which is why they matter so much in education.
Capability outcomes reside in what the user can now do. Capability expansion makes previously out-of-reach tasks possible. Productivity gain reduces the time, effort, or cost for tasks the user could already perform. Access expansion gives the user access to reasoning, styles, or frameworks that would otherwise be difficult to draw on. The amplification can be empowering, and it can also create overconfidence and overreliance, which is a tradeoff worth flagging explicitly with students.
Artifact outcomes reside in what gets produced. Expression quality is clarity, polish, persuasiveness, contextual fit, usability. Generative novelty is a form, content, or combination that is surprising relative to a reasonable baseline. Representation is whose perspectives, traditions, examples, and contributors appear. A prompt can reproduce dominant defaults or contest them, and in education we should be teaching students to make this choice consciously.
Task outcomes reside in the task that is accomplished. A problem solved, a decision made, a calculation completed, a message sent, an error found, a plan executed, a workflow completed. Task outcomes are the most external locus of value and the one that prompt engineering benchmarks usually measure. They are essential, and they are also not the whole story. A prompt that produces insight but fails to answer the user's practical question may be educationally valuable while remaining task-inadequate. A prompt that produces a polished artifact but gives the wrong answer has failed in a crucial respect. The framework helps users recognize which outcomes matter for a specific task and design accordingly.

The New Interface of Knowledge Work
I built this framework because I wanted to provide students with something better than just a few simple remarks on the importance of specification, context, clarity, and examples that are often mentioned in discussions of prompt engineering or prompt design. I wanted to think more deeply about what makes a prompt valuable.
Prompting is becoming the most important interface in knowledge work. The quality of what we get out of AI systems depends substantially on the quality of what we put in. And the gap between a non-trivial prompt and an intuitive one is widening, because the systems are getting more capable and the moves that exploit those capabilities are getting more sophisticated. Studies of non-expert users consistently find that mental models of how these systems work are weak and that iteration strategies are underdeveloped. We need a vocabulary that helps people see what they are doing when they prompt, what they could be doing instead, and how to tell the difference.
The framework should be used as analytical lenses and not a checklist. A dimension may be absent, implicit, weakly exercised, or deeply exercised depending on the task. A simple factual lookup doesn't need expertise priming or system coordination. A complex professional design task may need all seven dimensions exercised with all four qualities, in service of multiple outcomes at once. Skilled prompt crafting is recognizing which moves matter for this task, making them well, and orienting them toward the right kind of value.
If you teach generative AI literacy or write about prompting, I would love to hear how the framework lands for you, where the categories feel airtight, and where they still feel fuzzy.
Member discussion